Đồ Án Xử Lý Tiếng Nói
Đề bài:
- Hướng nghiên cứu: Tìm hiểu các giải pháp cho một vấn đề cụ thể trong lĩnh vực xử lý tiếng nói. Chọn một chủ đề trong xử lý/nhận dạng/tổng hợp tiếng nói; tìm hiểu, khảo sát và viết báo cáo về đề tài đó.
- Hướng ứng dụng: Tìm hiểu hoàn chỉnh một giải pháp cho một vấn đề cụ thể trong lĩnh vực xử lý tiếng nói. Xây dựng 1 ứng dụng, có sử dụng các công nghệ về xử lý/nhận dạng/tổng hợp tiếng nói.
Deadline: Chủ nhật, 18 Tháng mười hai 2022, 11:00 PM
Hình thức nộp:
- Học viên ghi hình lại bài trình bày đề tài của mình
- Điền thông tin đề tài và link video trong ô "Online Text"
- Upload slide và tài liệu tương ứng lên Moodle
(Lịch vấn đáp sẽ được thông báo sau)
Đề tài: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Paper: https://arxiv.org/abs/2106.06103
kim21f.pdf
- Motivation
- Định nghĩa bài toán
- Related Works
- Phương pháp
- Dữ liệu
- Thực nghiệm
- Kết quả
- Kết luận
1. Motivation ^ba93f2
End-to-end * text-to-speech* các nghiên cứu có hỗ trợ single stage training và parrallel sampling, nhưng không khớp với hệ thống 2 stage của TTS. Do đó bài báo đề xuất phương pháp generate tiếng nói hiệu quả hơn 2 stage model.
Model sử dụng variatioinal inference augumented với normalizing flow và adversarial training process (giúp tăng khả năng generative của model).
Model outperform state of the art
2. Định nghĩa bài toán
- TTS là hệ thống tổng hợp tiếng nói (raw speech waveform) từ một đoạn text cho trước.
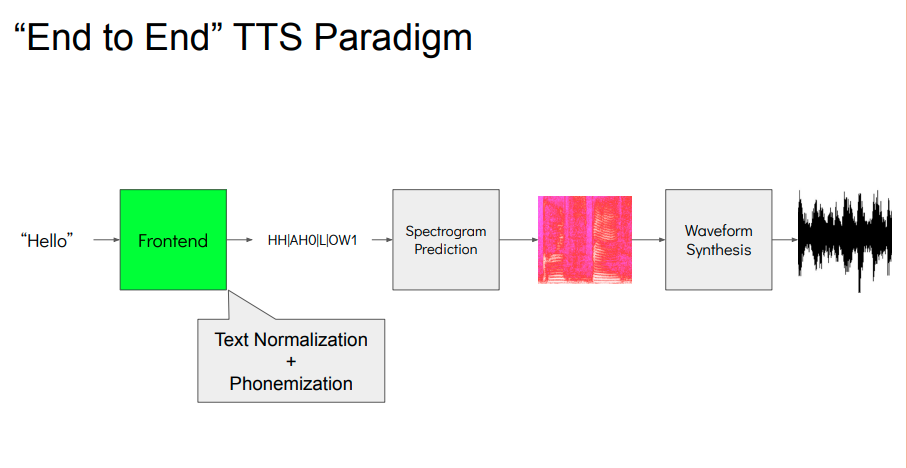
- Hệ thống được chia thành 2 phần (2 stage):
- rút trích intermediate speech representation (mel-spectograms hoặc linguistic features) từ input text.
- generate raw waveform dựa trên intermediate representation ở stage 1.
- 2 models được train độc lập. Cần phải train theo tứ tự: stage 1 -> stage 2. Paper giải quyết bài toán training bằng cách train song song 2 stage.
3. Related Works
- Network-based autoregressive TTS system hiệu quả nhưng do tính chất "sequential genereative process" làm cho nó khó có thể chạy song song. Do đó nhiều nghiên cứu sử dụng non-autoregressive được đưa ra.
- Tại bước text-to-spectogram: rút trích attention maps từ pre-trained autoregressive teachnet giảm độ khó của việc học alignment giữa text và spectogram.
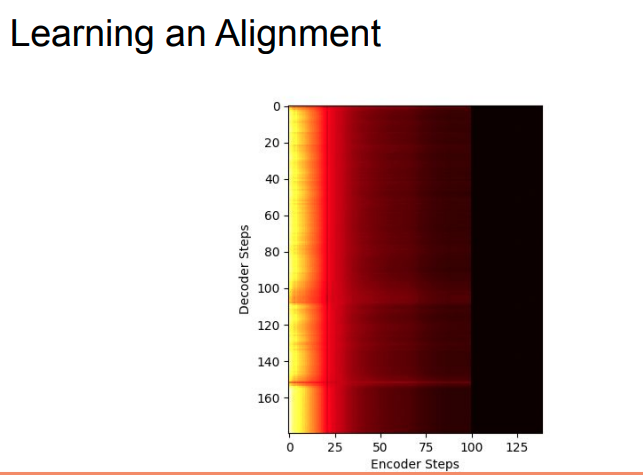
- Tiếp đến, likelihood-based method giúp giảm sự phụ thuộc vào external aligner bằng cách estimate hoặc học align với mục tiêu maximize log likelihood của target spectogram.
- Ở stage 2, GANs-based method sử dụng multiple discriminators, "each distinguishing samples at different scales or periods" cho kết quả raw waveform chất lượng cao hơn.
- Tại bước text-to-spectogram: rút trích attention maps từ pre-trained autoregressive teachnet giảm độ khó của việc học alignment giữa text và spectogram.
- End-to-End training như FastSpeed 2s, EATS train trên short audio clips --> levarageing a mdel-spectrogram decoder to aid text representation learning và đề xuất một hàm loss đặc biệt cho spectogram để giải quyết vấn đề 2 độ dài audio khác nhau giữa target và generated speech. Mặc dù hiệu quả và có khả năng cải tiến, nhưng chất lượng của generated speech vẫn thấp hơn 2-stage model.
Trong bài báo này, nhóm tác giả giới hiệu mô hình TTS song song, out perform 2-stage method. Sử dụng VAE để kết nối 2 modules. Để đạt được waveform chất lượng cao, họ áp dụng normalizing flow vào "conditional prior distribution" và adversarial training (wavefom domain).
Ngoài việc phải generate waveform chất lượng tốt, hệ thống cùng cần phải "express" quan hệ one-to-many (một từ có thể có nhiều cách đọc, cách nói, tông cao, thấp, trầm, bổng, dài, ngắn, etc), nhóm tác giả đề xuất "stochatic duration predictor" để tổng hợp speech với đa dạng rhythms từ input text. Với uncertainty từ latent space và stochatic predictor model của đề xuất có thể rút trích được các "speech variation" không được biểu diễn trong text.
4. Phương Pháp
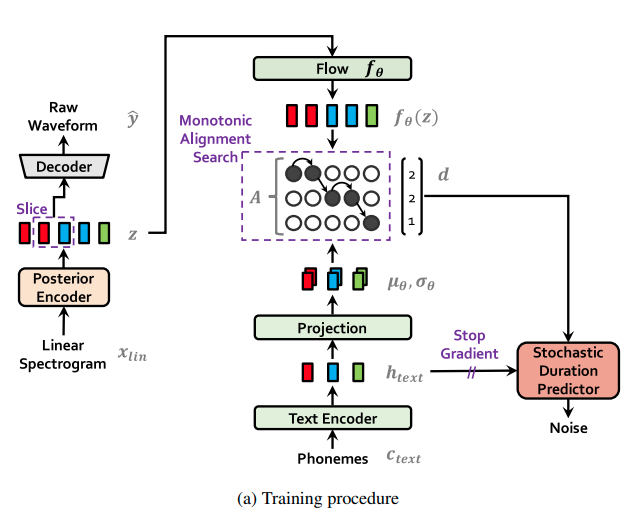
- Gồm 2 phần chính:
- conditional VAE fomulation: estimate alignment từ variational inference
- adversarial training: cải thiện chất lượng synthesic
4.1 Variational Inference
VITS tối ưu hàm mục tiêu maximize variational lower bound (ELBO)
$$\log{p_{\theta}(x | c)} \ge E_{q_{\phi}(z | x)} [\log p_{\theta}(x | z) - log\frac{p_{\phi}(z | x)}{p_{\theta}(z|c)} ]$$
Training loss là negative ELBO, bằng tổng của reconstruction loss và KL divergence.
4.1.1 Reconstruction loss
Về reconstruction loss, nhóm tác giả sử dụng mel-spectogram để tính loss thay vì waveform #why . Đầu tiên upsampling latent variable z sang waveform domain y^hat thông qua decoder và transform y^hat sang mel-spectogram. Sau đó, sử dụng L1 để tính loss giữa prediction spectogram và target mel-spectogram.
$$L_{recon} = || x_{mel} - \hat{x}_{mel} ||$$
Sử dụng mel-spectogram để tính loss để cải thiện perceptual quality dùng mel-scale approximate the response từ human audit system. Mel-spectogram transform không yêu cầu trainning, nó là một hàm linear projection với parameter là STFT. Phần này chỉ dùng trong training, không sử dụng ở bước inference.
Với thực nghiệm, nhóm tác giả không upsampling toàn bộ latent variable $z$ mà chỉ sử dụng một phần của sequence làm input cho decoder (window generator cho efficient training)
4.1.2 KL-Divergence
Input đầu vào của prior encoder $c$ được kết hợp từ $c_{text}$ rút trích từ text và alignement $A$ giữa phonemes và latent variable.
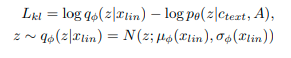
#TODO hoàn thành phần này, chưa hiểu input là gì
4.2 Alignment Estimation
4.2.1 Monotonic Alignment Search
Để estimate alignment $A$ giữa text input với target speed, nhóm tác giả sử dụng Monotonic Alignment Search, là một phương pháp tìm kiếm alignment mà tối đa hàm likelihood của data bằng một normalizing flow f:
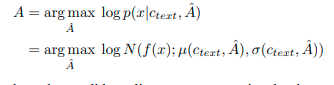
Với đối tượng alignment được giới hạn trong nhóm monotonic và non-skipping theo cách con người đọc câu theo thứ tự mà không bỏ bất kì từ nào. Để tìm lời giải tối ưu, sử dụng dynamic programming, ứng dụng MAS trức tiếp rất khó, do hàm mục tiêu là ELBO, không thực chất là log likelihood. Do đó, họ định nghĩa lại MAS để tìm alignment tối đa hàm mục tiêu ELBO:
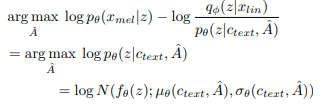
4.2.2 Duration Prediction From text
Duration của mỗi input token $d_i$ được tính bằng tổng các cột trong mỗi row của estimation alignments $\sum_j{A_{i, j}}$ . Một network khác có thể dụng dữ liệu duration để huấn luyện một bộ duration prediction, nhưng nó không mô tả được cách mà một người phát ra tiếng khác nhau trong mỗi lần. Để tạo ra tiếng có nhịp điệu tự nhiên giống con người, nhóm tác giả đề xuất một stochatic duration predictor sử dụng dữ liệu mẫu từ duration distribution của phonemes, predictor này là một flow-based generative model được train thông qua tối đa hóa hàm likelihood. Vấn đề là tối đa hóa hàm này rất kho do mỗi input phoneme là một số integer rời rạc dẫn đến việc phải chuyển rời rạc sang dạng continuous. Thứ hai là nó là một số, do đó khó khăn trong high-dimension transformation do vấn đề khả năng nghịch đảo. Nhóm tác giả sử dụng variational dequantization và variational data augumentation để giải quyết các vấn đề trên. Cụ thể, 2 biến ngẫu nhiên là $u$ và $v$ có cùng time resolution và dimension ví dụ như là duration sequence $d$ . Kết quả hàm mục tiêu là variational lower bound của log likelihood của phoneme duration:
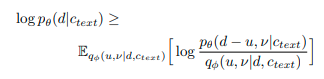
4.3 Adversarial Traiing
Để ứng dụng adversairal training, nhóm tác giả thêm một discriminator $D$ để phân biệt giữa ouptut được tạo ra từ decoder $G$ và ground truth waveform $y$ . Nhóm tác giả sử dụng 2 dạng hàm loss: least-square loss (cho adversarial training) và matching loss (cho training generator)
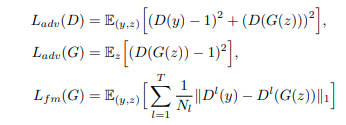
trong đó $T$ là tổng số layer trong discriminator và $D^l$ output feature map của layer thứ $l$ của discriminator với $N_l$ số features.
4.4 Final Loss
Kết hợp VAE và GAN trong việc training, tổng loss như sau:
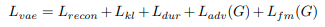
4.5 Model Architecture
Tổng quan hệ thông gồm 1 posterior encoder, prior encoder, decoder, discriminator và stochatic duration predictor. Trong đó posterior encoder và discriminator chỉ sử dụng trong quá trình huấn luyện.
Đối với posterior encoder, nhóm tác giả sử dụng WaveNet residual block.
Prior encoder bao gồm text encoder xử lý input phonemes $c_{text}$ và normalizing flow $f_{\theta}$ cải thiện sự linh hoạt của prior distribution. Text encoder là một dạng transformer encoder có sử dụng relative positional representation thay vì absolute position encoding. Normalizing flow sử dụng một dãy các layer affine bao gồm một loạt các Wavenet residual block.
Decoder sử dụng lại từ HiFi-GAN V1 generator, bao gồm dãy các convolutions theo sau là một multireceptive field fusion module. Output của nó là tổng các ouput của residual block có các receptive khác nhau. Đối với trường hợp multi-speaker, họ thêm một linear layer để transform speaker embedding và cộng nó vào input latent variable $z$.
Discriminator, nhóm tác giả sử dụng multi-period discriminator cũng lấy từ HiFi-GAN, bao gồm một hỗn hợp các Markovian window-based sub-discriminators, mỗi cái sẽ xử lý một đoạn của input waveform.
Stochatics duration predictor estimate phân bố duration của phoneme từ một input có điều kiện $h_{text}$ ,
5. Thực nghiệm
5.1 Dữ liệu
Nhóm tác giả thực nghiệm trên 2 bộ dữ liệu: LJ Speech dataset và VCTK dataset. Trong đó, bộ đầu tiên để lấy kết quả so sánh với các method khác. Bộ thứ 2 dùng để đánh giá model có thể học đa dạng các cách biễu đạt trong câu.
Bộ LJ Speech chứa 13,100 short audio clip của một speaker với thời lượng vào khoảng 24 giờ.
Bộ VCTK gồm 44,000 short audio clip của 109 native English speaker với nhiều giọng (accent) khác nhau. Tổng thời lượng rơi vào khoảng 44 giờ.
5.2 Tiền xử lý
Nhóm tác giả sử dụng Short-time Fourier transform (STFT) để chuyển waveform về dạng linear spectogram, cái này được dùng làm input cho posterior encoder.
FFT size: 1024
window size: 1024
hop size: 256
Họ sử dụng spectogram với thang đo mel-scale gồm 80 bands để tính loss. Và sử dụng International Phonetic Alphabet (IPA) sequence như là input cho prior encoder, đồng thời chuyển câu sang IPA phoneme bằng open-source.
5.3 Huấn luyện
Sử dụng Adam optimizer, window generator training, một phương pháp để chỉ tạo một phần waveform từ raw waveform giúp giảm thời gian huấn luyện cũng như bộ nhớ trong quá trình huấn luyện. Ngẫu nhiên chọn segment của latent representation với window size là 32 để đưa vào decoder, thay vì lấy toàn bộ latent feature, thêm nữa là rút trích phần audio segment tương ứng trong ground truth để làm target.
6. Kết quả
6.1 Speech Synthesis Quality
Nhóm tác giả tiến hành crowd-sourced MOS tests để đánh giá chất lượng. Người gán nhãn sẽ được cho nghe ngẫu nhiên một đoạn audio mẫu và đánh giá tính tự nhiên của đoạn thoại theo thang đo từ 1 đến 5 (tự nhiên nhất), các đoạn audio đã được chuẩn hóa để độ lớn (amplitude) không ảnh hưởng đến kết quả.
Kết quả được biểu diễn dưới bảng sau, VITS cho kết quả out perform các model TTS khác và đạt gần với kết quả ground truth.
Model VITS (DDP) sử dụng deterministic duration predictor của Glow-TTS thay vì stochatic duration predictor cho kết quả cao hơn trong các model còn lại. Kết quả cho thấy stochatic duration predictor cho output có duration chân thực hơn deterministic duration predictor. Và end-to-end training hiệu quả hơn các phương pháp TTS khác.

Để đánh giá tính hiệu quả của normalized flow trong prior encoder và linear-scale spectrogram posterior input, nhóm tác giả tiến hành huấn luyện các model có sử dụng và không có sử dụng các đề xuất. Kết quả như bảng dưới.
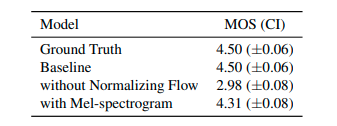
Model không sử dụng normalizing flow chỉ đạt 2.98 MOS nhỏ hơn 1.52 so với baseline, cho thấy prior distribution có ảnh hưởng lớn tới chất lượng của output. Ngoài ra, thay thế linear-scale spectogram trong posterior input với mel-spectrogram làm giảm 0.19 MOS cho thấy thông tin về high-resolution có hiệu quả trong VITS giúp tăng chất lượng output.
6.2 Generalization to Multi-Speaker Text-to-Speech
Để đánh giá model có thể học và biễu đạt giọng nói đa dạng, nhóm tác giả so sánh model đề xuất với Tacotron2, Glow-TTS và HiFi-GAN. Model được huấn luyện trên bộ VCTK. Kết quả ở bảng dưới cho thấy, model đề xuất có kết quả cao hơn và ngang với grounth truth.

6.3 Speech Variation
Nhóm tác giả phân tích stochatic duration prediction cho ra bao nhiêu thời lượng khác nhau, và bao nhiêu đặc điểm giọng nói mà model tổng hợp được.
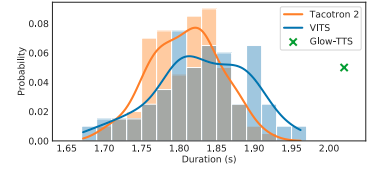
Biểu đồ trên so sánh thời lượng mẫu, của 100 đoạn được tạo từ mỗi model. Glow-TTS chỉ cho ra một thời lượng nhất định do sử dụng deterministic duration predictor. Model của tác giả đề xuất có phân bố thời lượng khá tương đồng với model Tacotron 2.
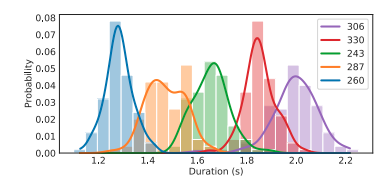
Biểu đồ trên so sánh thời lượng mẫu giữa các speaker, gồm 100 đoạn được tạo từ model đề xuất cho multi-speaker, cho thấy model học được phoneme duration của từng speaker.
Biểu đồ dưới so sánh đặc trưng trong đoạn được tạo, F0 counter của 10 đoạn rút trích bằng thuật toán YIN. Có thể thấy VITS cho ra kết quả đa dạng hơn về pitch và rhythm.
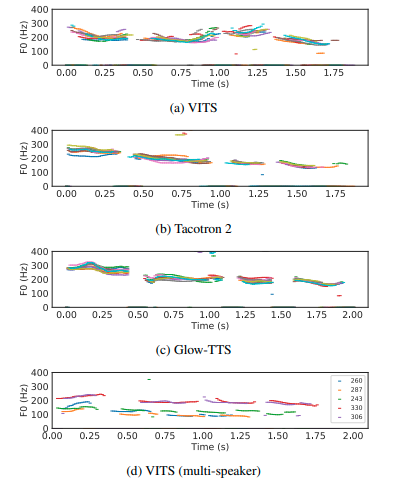
7. Kết luận
Nhóm tác giả đã đề xuất một hệ thống TTS song song, VITS có thể học và tạo tiếng nói end-to-end. Cũng như giới thiệu bộ stochatic duration predictor để biễu đạt đa dạng các loại rhythm. Kết quả cho thấy model cho ra giọng nói tự nhiên, và kết quả so sánh đạt được cao hơn các model khác, đạt gần so với con người.
#voice-conversion #text-to-speech